Code
remotes::install_github("mganslmeier/sensiverse")
library(readxl)
library(dplyr)
library(ggplot2)
library(stringr)
library(tidyr)
library(scales)
library(reticulate)
library(sensiverse)
theme_set(theme_minimal(base_size = 12))remotes::install_github("mganslmeier/sensiverse")
library(readxl)
library(dplyr)
library(ggplot2)
library(stringr)
library(tidyr)
library(scales)
library(reticulate)
library(sensiverse)
theme_set(theme_minimal(base_size = 12))We examine whether stronger left‐party representation in parliament is associated with greater women’s political representation and empowerment, and how sensitive that relationship is to different modelling choices.
We treat:
left_strength — combined seat share of social democratic and left‐socialist parties (from CPDS data integrated in QoG)ipu_l_sw – Women’s share in the lower or single chamber of parliamentwdi_wip – World Bank indicator of women in national parliamentsvdem_gender – V-Dem index of women’s political empowermentWe vary:
pwt_hci)wdi_internet)wdi_unempilo)vdem_libdem, democratization and governance)iaep_es)# ---- Load QoG Basic (Jan25) ------------------------------------
path_qog <- "data/qog_bas_ts_jan25.dta"
qog <- haven::read_dta(path_qog)
# Helper: pick first present name among candidates (keeps script robust across QoG formats)
find_col <- function(df, cands, label) {
hit <- intersect(cands, names(df))
if (!length(hit)) stop(sprintf("Missing variable: %s (looked for: %s)", label, paste(cands, collapse=", ")))
hit[1]
}
# Core IDs (QoG typically uses cname for country names)
country_col <- find_col(qog, c("cname","country","CNAME"), "country")
year_col <- find_col(qog, c("year","Year"), "year")
# Focus IV: Left strength = social democratic + left-socialist seat shares
cpds_ls_col <- find_col(qog, c("cpds_ls"), "CPDS social democratic seats")
cpds_lls_col <- find_col(qog, c("cpds_lls"), "CPDS left-socialist seats")
# Outcomes (DVs)
ipu_l_col <- find_col(qog, c("ipu_l_sw"), "IPU women share lower/single house")
wdi_wip_col <- find_col(qog, c("wdi_wip"), "WDI women in parliament")
vdem_gender_col <- find_col(qog, c("vdem_gender"), "V-Dem women political empowerment")
# Controls
pwt_hci_col <- find_col(qog, c("pwt_hci"), "Human capital index (PWT)")
wdi_internet_col<- find_col(qog, c("wdi_internet"), "Internet users (% pop)")
wdi_unemp_col <- find_col(qog, c("wdi_unempilo"), "Unemployment (ILO modeled)")
vdem_libdem_col <- find_col(qog, c("vdem_libdem"), "Liberal democracy index")
iaep_es_col <- find_col(qog, c("iaep_es"), "Electoral system (IAEP)")nordics <- c("Denmark","Finland","Iceland","Norway","Sweden")
anglo <- c("United Kingdom","United States","Canada","Australia","New Zealand","Ireland")
continental <- c("Germany","France","Netherlands","Belgium","Austria","Switzerland","Luxembourg")
dat <- qog %>%
transmute(
country = .data[[country_col]],
year = .data[[year_col]],
# DVs
DEP_ipu_l_sw = .data[[ipu_l_col]],
DEP_wdi_wip = .data[[wdi_wip_col]],
DEP_vdem_gender = .data[[vdem_gender_col]],
# Focus IV: Left strength = cpds_ls + cpds_lls (sum available parts), then scale
left_strength_raw = dplyr::coalesce(.data[[cpds_ls_col]], 0) +
dplyr::coalesce(.data[[cpds_lls_col]], 0),
CONT_left = as.numeric(scale(left_strength_raw)),
# Controls (scaled for comparability)
CONT_hci = as.numeric(scale(.data[[pwt_hci_col]])),
CONT_internet = as.numeric(scale(.data[[wdi_internet_col]])),
CONT_unemp = as.numeric(scale(.data[[wdi_unemp_col]])),
CONT_libdem = as.numeric(scale(.data[[vdem_libdem_col]])),
# PR vs non-PR: IAEP electoral system = 3 (PR) or 4 (Mixed) -> treat as PR=1 (common practice in comp. pol.)
pr_flag = dplyr::case_when(.data[[iaep_es_col]] %in% c(3,4) ~ 1L,
.data[[iaep_es_col]] %in% c(1,2) ~ 0L,
TRUE ~ NA_integer_),
CONT_pr = as.numeric(scale(pr_flag)),
FEgroup = .data[[country_col]],
FEtime = .data[[year_col]]
) %>%
mutate(
SAMPLE_all = 1L,
SAMPLE_1990_2008 = as.integer(year >= 1990 & year <= 2008),
SAMPLE_post2009 = as.integer(year >= 2009),
SAMPLE_nordics = as.integer(country %in% nordics),
SAMPLE_anglo = as.integer(country %in% anglo),
SAMPLE_continental = as.integer(country %in% continental)
) %>%
# Require focus IV + at least one DV observed
filter(!is.na(CONT_left) & (!is.na(DEP_ipu_l_sw) & !is.na(DEP_wdi_wip) & !is.na(DEP_vdem_gender)))specs <- list(
dep = c("DEP_ipu_l_sw","DEP_wdi_wip","DEP_vdem_gender"),
cont = c("CONT_left","CONT_hci","CONT_internet","CONT_unemp","CONT_libdem","CONT_pr"),
fes = c("none","group","time","time+group"),
set = c("simple","robust","clustered"),
sample = c("SAMPLE_all", "SAMPLE_1990_2008","SAMPLE_post2009",
"SAMPLE_nordics","SAMPLE_anglo","SAMPLE_continental")
)res <- estimate_model_space(
df = dat,
focus_var = "CONT_left",
specs = specs,
space_n = 5000
)res_filt <- filter_model_space(res, top_aic_pct = 0.25)shares_all <- calculate_sign_shares(res, dimension = NULL)
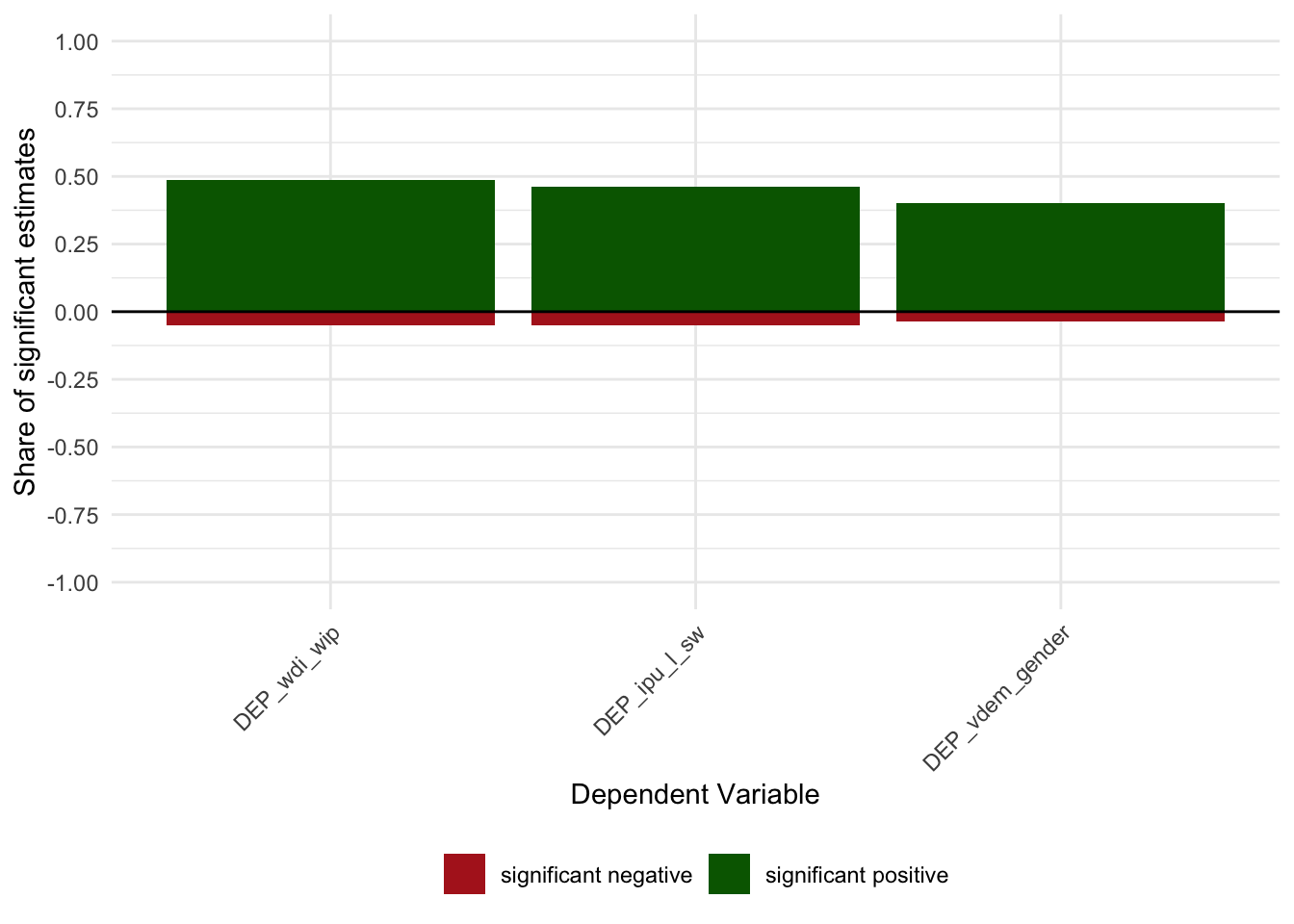
shares_allfor (d in c("dep","fes","set","sample")) {
s <- calculate_sign_shares(res, dimension = d)
print(plot_sign_share(s, dimension = d))
}
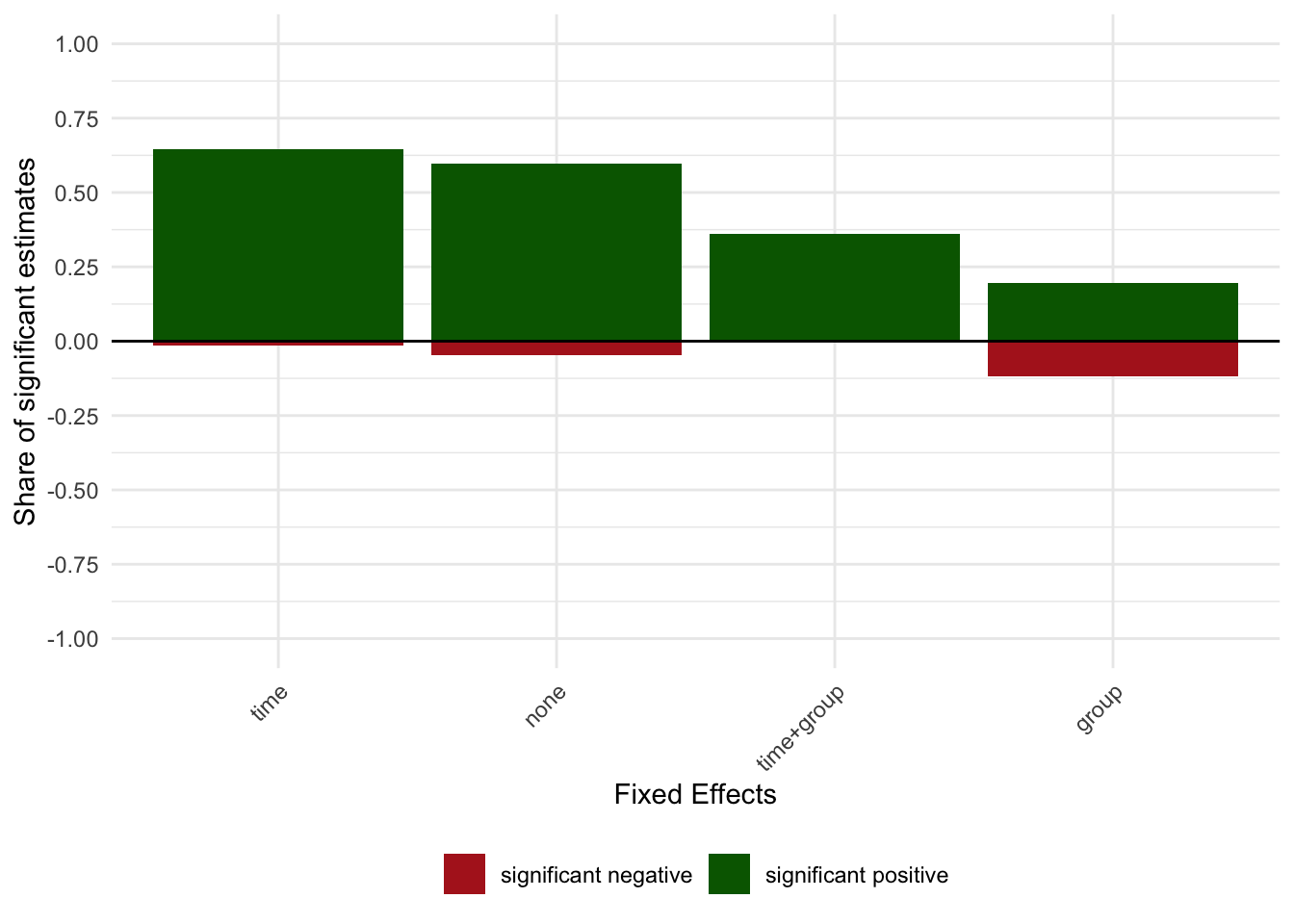
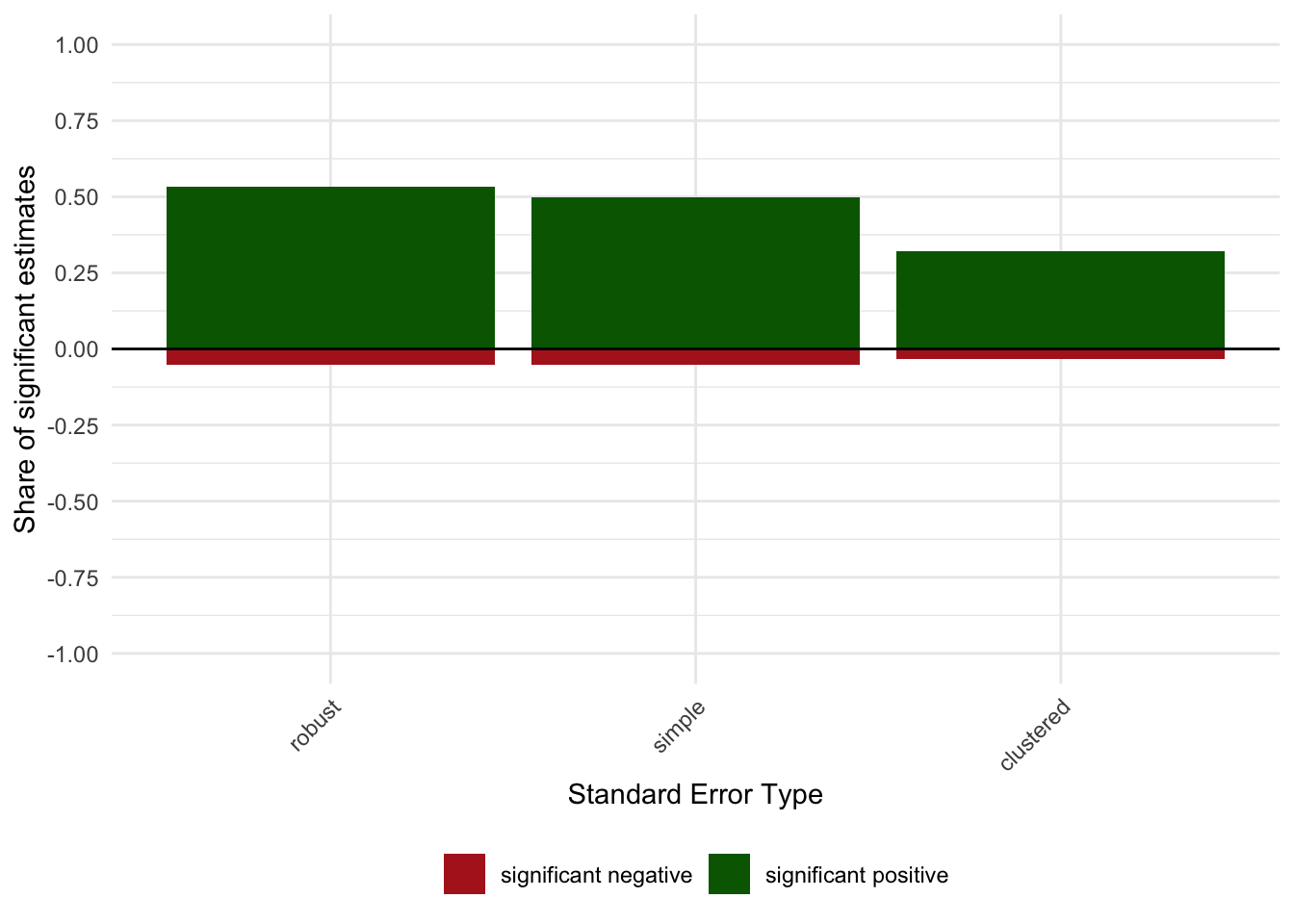
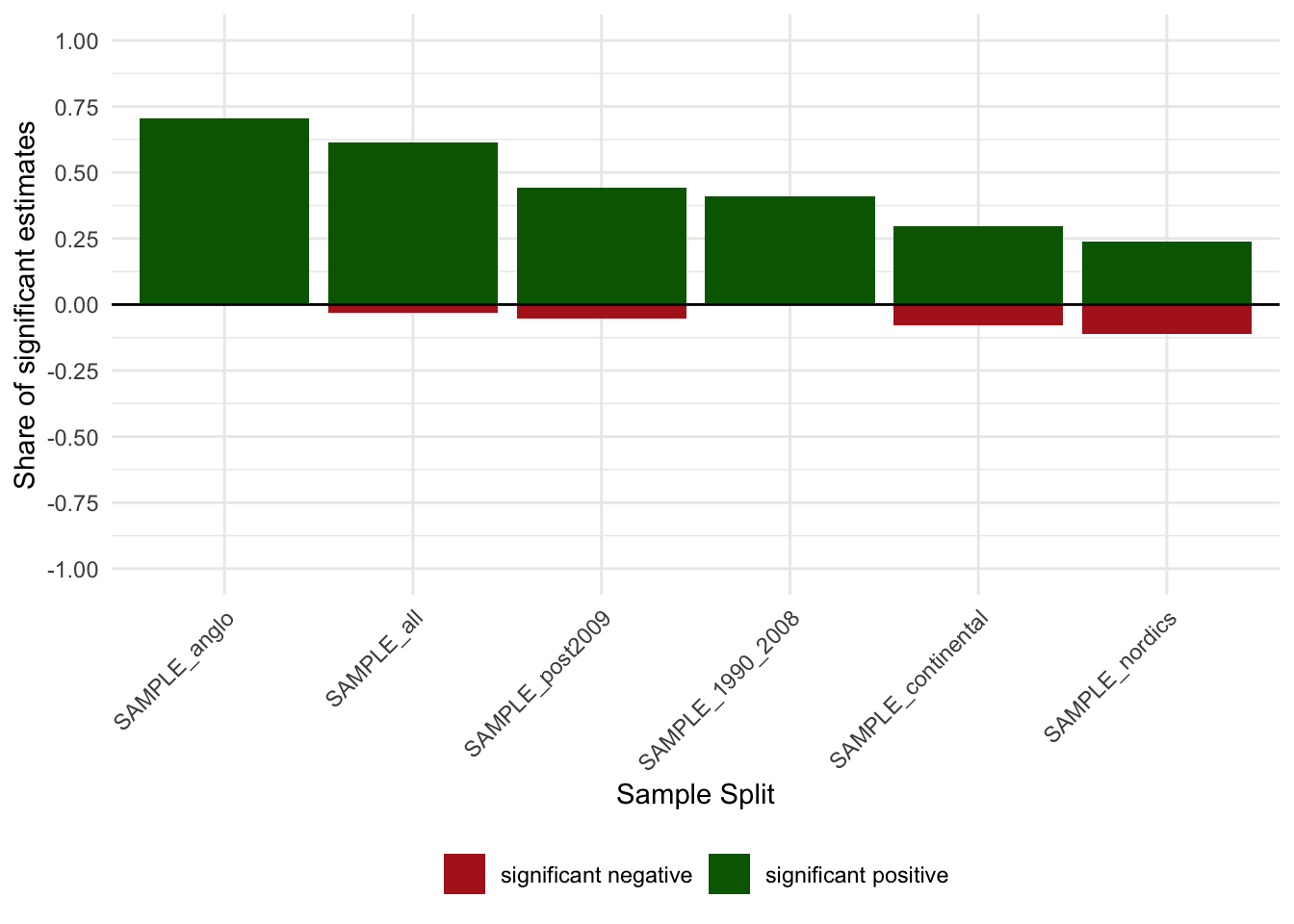
nn_out <- find_uncertainty_source_neigh(
specs = specs,
df = dat,
focus = "CONT_left",
n_draws = 400,
seed = 2025
)
plot_importance_neigh(nn_out)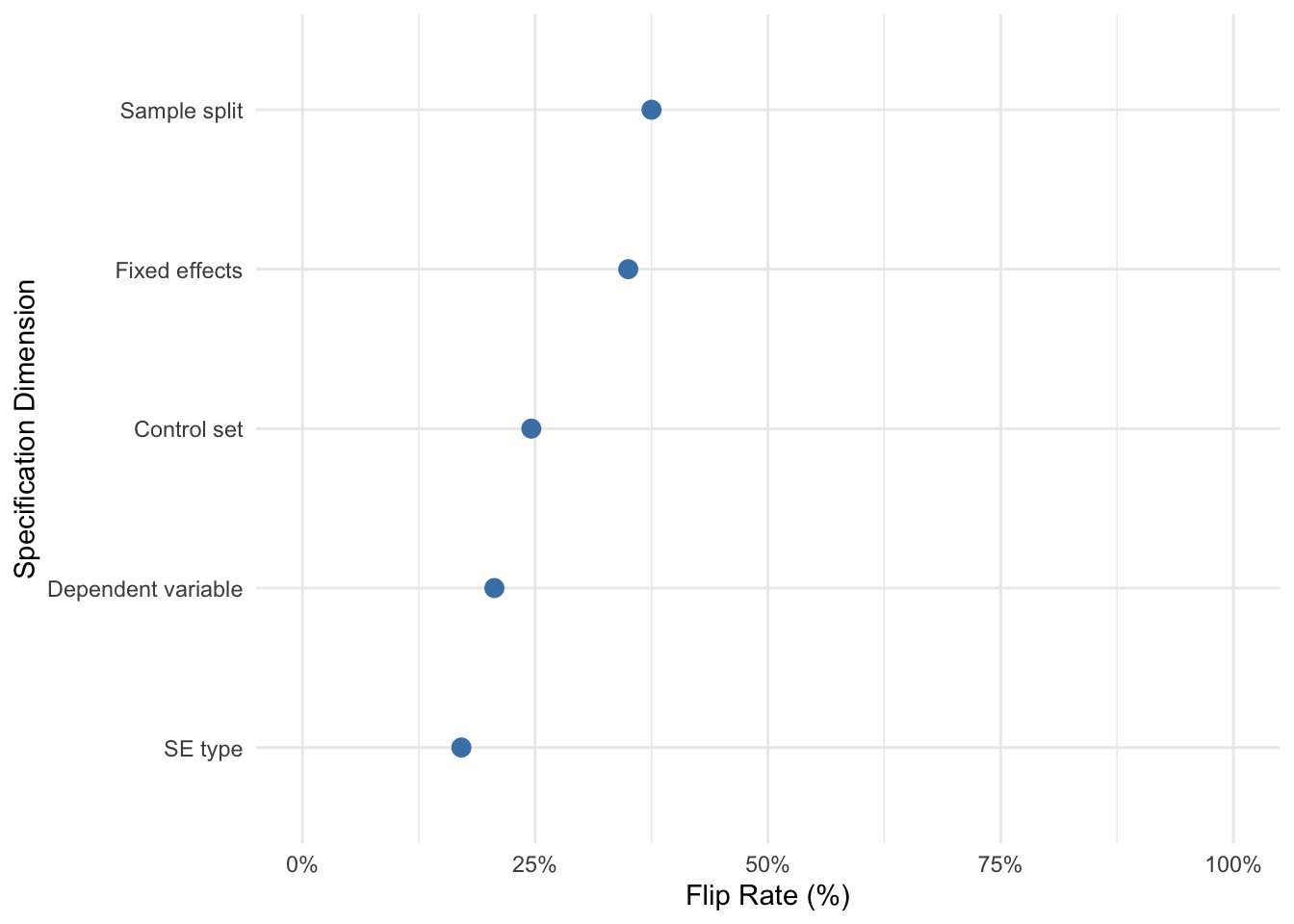
mlogit_out <- find_uncertainty_source_mlogit(res, focus="CONT_left")
plot_importance_mlogit(mlogit_out, aggregate=TRUE)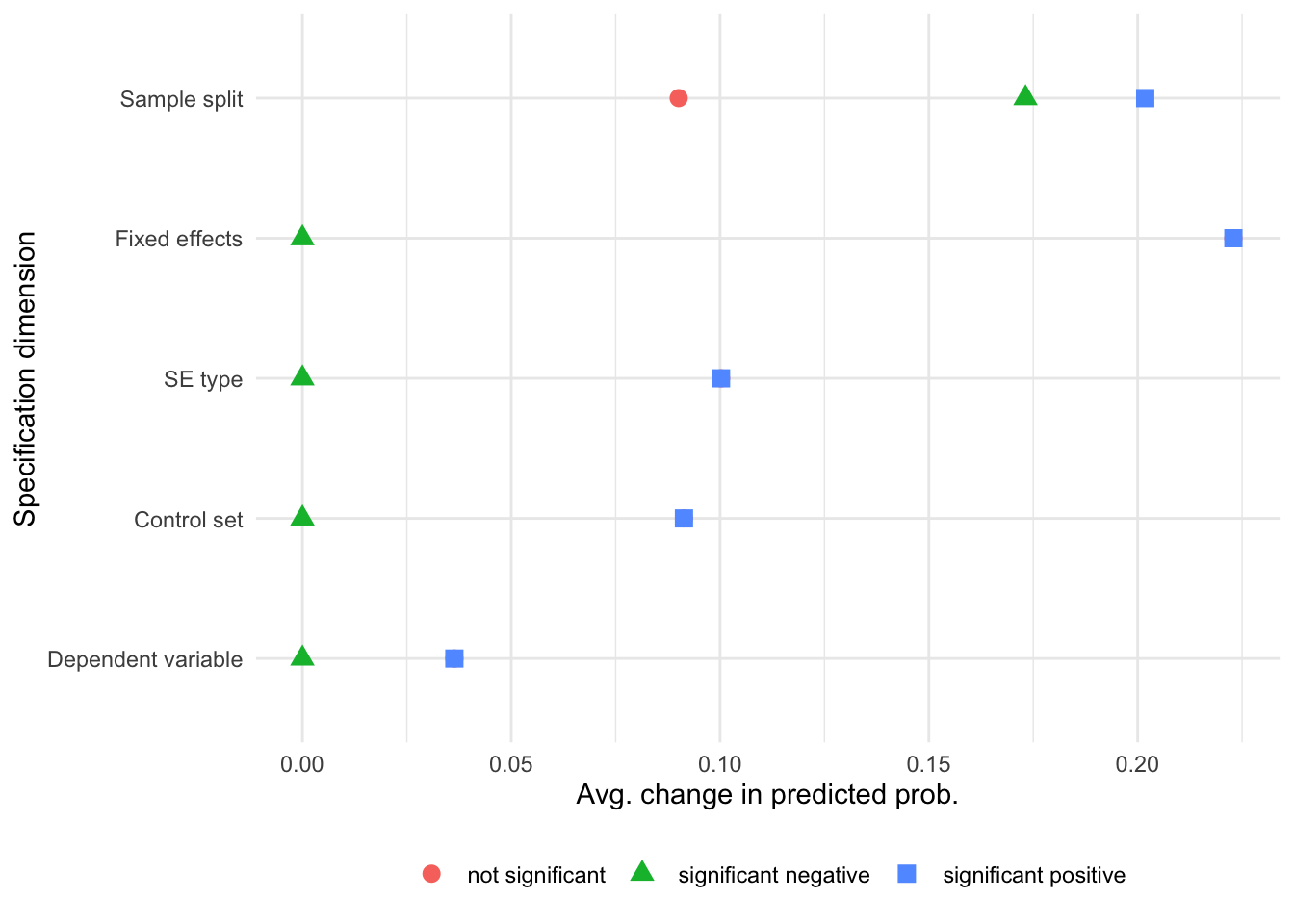
plot_importance_mlogit(mlogit_out, aggregate=FALSE)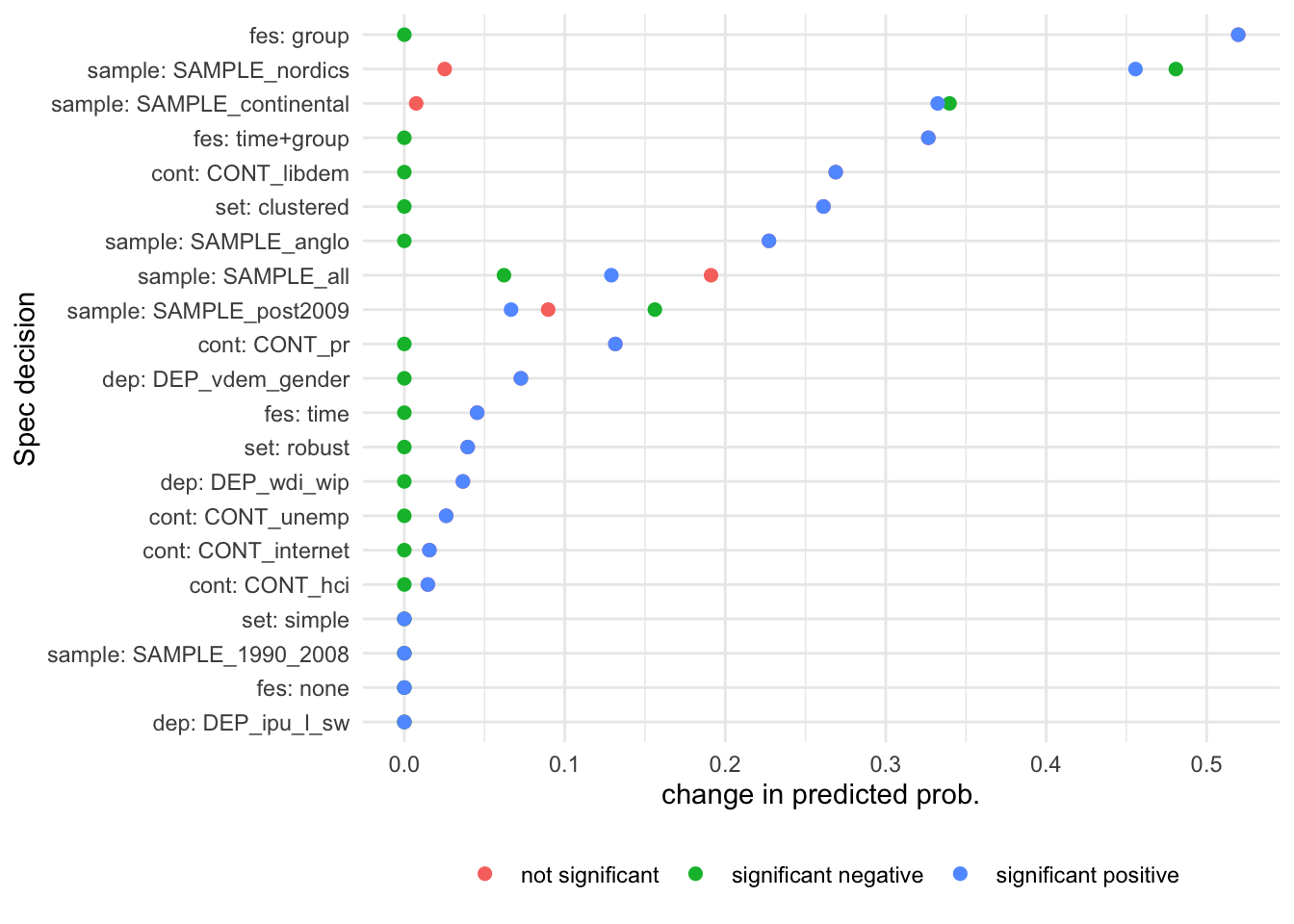
# install.packages(c("keras","vip"))
# keras::install_keras()
# use_python("~/miniforge3/bin/python") # make sure you use the correct python and tensorflow version
# use_condaenv("tf_env")
nn_out <- find_uncertainty_source_neuronet(
res = res,
focus = "CONT_left",
epochs = 15,
batch_size = 256,
verbose = 0
)
p1 <- plot_importance_neuronet(nn_out, aggregate = TRUE)
p2 <- plot_importance_neuronet(nn_out, aggregate = FALSE)
plot(p1)
plot(p2)